
Open source
Journaux liées à cette note :
Script qui permet de transformer automatiquement du texte en anglais en fichier audio
J'ai généré avec Claude Sonnet 4.5 le script Python text_to_audio.py. Il me permet de transformer automatiquement du texte en anglais en fichier audio mp3.
J'intègre ensuite ces fichiers dans mes carte-mémoire Anki pour travailler mon anglais.
Installation sous Fedora :
$ mkdir -p ~/.local/bin
$ curl -o ~/.local/bin/text_to_audio.py https://gist.githubusercontent.com/stephane-klein/1406e746f0253956062d4adff7a692bd/raw/8571cdd91cae8ebcd208435daacf431cfc1cd353/text_to_audio.py
$ chmod +x ~/.local/bin/text_to_audio.py
Exemple d'utilisation :
$ text_to_audio.py "Reinforcement Learning from Human Feedback"
Downloading audio for: 'Reinforcement Learning from Human Feedback'
Language: en-GB
URL: https://translate.google.com/translate_tts?ie=UTF-8&tl=en-GB&client=tw-ob&q=Reinforcement+Learning+from+Human+Feedback
Saving to: /home/stephane/english_audio/2025-12-01_Reinforcement_Learning_from_Human_Feedback.mp3
✓ Successfully downloaded to '/home/stephane/english_audio/2025-12-01_Reinforcement_Learning_from_Human_Feedback.mp3'
File size: 28224 bytes
J'utilise actuellement un endpoint HTTP de Google Translator pour générer les fichiers audio, en attendant de trouver une alternative plus open source / communautaire.
Setup Fedora CoreOS avec LUKS et TPM, non sécurisé contre le vol physique de serveur
Comme je l'ai dit dans cette précédente note, jusqu'il y a peu de temps, je ne m'étais jamais intéressé et j'avais même évité les technologies liées aux trusted computing.
Il y quelques jours, j'ai testé avec succès l'installation d'une Fedora CoreOS avec une clé de déchiffrement LUKS sauvegardée dans une puce TPM2 à l'aide de clevis.
Grâce à TPM, cette configuration évite de devoir saisir la clé de déchiffrement au moment du boot de l'OS.
Je trouve cette approche particulièrement pertinente sur une distribution CoreOS qui utilise zincati pour appliquer automatiquement les mises à jour de l'OS à des horaires définis (voir note à ce sujet).
Pour tester cette configuration, j'ai créé le playground install-coreos-iso-on-qemu-with-luks , qui me permet de tester localement l'installation dans une VM QEMU.
Pour émuler le TPM2, j'utilise swtpm et le BIOS UEFI Open source edk2-ovmf .
Dans ce test, j'ai choisi de créer et de chiffrer une partition pour stocker les données du dossier /var/, qui sur CoreOS est l'emplacement qui contient les données mutables (accessibles en écriture).
Voici la configuration butane de LUKS encryption avec les options TPM2 et clevis que j'ai utilisées (fichier complet) :
storage:
disks:
- device: /dev/nvme0n1
wipe_table: false
partitions:
- number: 4
label: root
size_mib: 15000
resize: true
- number: 5
label: var <=== label
size_mib: 0 # 0 = use all remaining space
luks:
- name: var <=== label
device: /dev/disk/by-partlabel/var
wipe_volume: true
key_file:
inline: password
clevis:
tpm2: true
filesystems:
- path: /var
device: /dev/mapper/var
format: xfs
wipe_filesystem: true
label: var
with_mount_unit: true
Je trouve le contenu de ce fichier de configuration assez simple et explicite.
J'ai ensuite créé un second playground install-coreos-iso-on-baremetal-with-luks.
L'installation automatique s'est déroulée sans problème sur un serveur baremetal.
J'ai testé la désactivation de TPM2 dans le BIOS : la console m'a alors demandé de saisir la clé manuellement. C'est plutôt pratique en cas de problème TPM, branchement du disque sur une autre machine…
La clé de chiffrement LUKS n'est pas stockée en clair dans le fichier ISO, il n'est donc pas nécessaire de sécuriser l'accès à ce fichier.
Attention, j'ai découvert que cette méthode n'est pas sécurisée en cas de vol physique du serveur !
Si un attaquant boot depuis un autre disque avec le même firmware et le même kernel, il pourra extraire en clair la clé LUKS stockée dans le TPM 🫣.
D'après mes recherches, la seule approche qui semble permettre à la fois la protection contre le vol physique et le reboot automatique serait d'utiliser clevis avec un serveur tang plutôt que le TPM.
Je compte tester cette configuration dans les prochaines semaines (depuis, cette note a été publiée : Setup Fedora CoreOS avec LUKS et Tang).
Journal du lundi 29 septembre 2025 à 18:57
#OnMaPartagé ce projet d'imprimante Open source : Open Printer.
J'adore l'idée 🙂.
Articles qui parlent de ce projet :
- The Open Printer Is a Raspberry Pi Zero W-Powered, Fully-Open, Highly-Flexible Inkjet Printer
- Reddit : One Step Closer to an All-in-one Modern Word Processor: A Compact, Open-Source Printer/
Pour le moment, aucun commentaire sur Hacker News :
J'ai découvert l'outil de build Javascript avec cache remote nommé "nx"
En étudiant un projet privé professionnel, #JaiDécouvert le projet nx qui est comme Turborepo un outil de build pour Javascript et TypeScript.
Pour commencer, je dois préciser que je n'apprécie pas du tout comment le projet se présente. On voit partout :
Cela me donne l'impression que ce "pitch" a été créé par une équipe marketing 🙉 !
J'ai découvert ce tout petit thread Hacker News qui date du 18 août 2022 sur Hacker News qui, je trouve, explique très bien le but de Nx :
I'm a core team member of Nx (nx.dev) and one of the core features we implemented quite a while ago, is "computation caching". Basically to speed up things, we get all the input to a given computation, which our case as a devtool means running your Jest tests, Webpack/esbuild/... build etc, and cache the result (logs & potential build artifacts).
Next time when the same computation is run, we look it up and restore it from the cache, obviously tremendously improving the speed of the run. The real value is when you distribute that cache among co-workers, CI agents etc., which you can do with Nx Cloud (nx.app).
We had played with the idea of potentially mapping this to CO2 emissions. If you start saving a lot of computation, this reduces the number of times a machine gets spin up & executed on your CI. Well, earlier this week we aggregated some stats of how much time we saved and we were pretty by the result ourselves!
I summed it up in this blog article: https://blog.nrwl.io/helping-the-environment-by-saving-two-centuries-of-compute-time-feea8e1ce22?source=friends_link&sk=9b1259d0b171a7b95ebe95b3795660b5
But basically we saved:
- last 7 days: ~5 years of compute time
- last 30 days: ~23 years
- since beginning of Nx Cloud: ~200 years
Je pense que ces mesures font référence à ce qu'on peut voir dans ce screenshot :
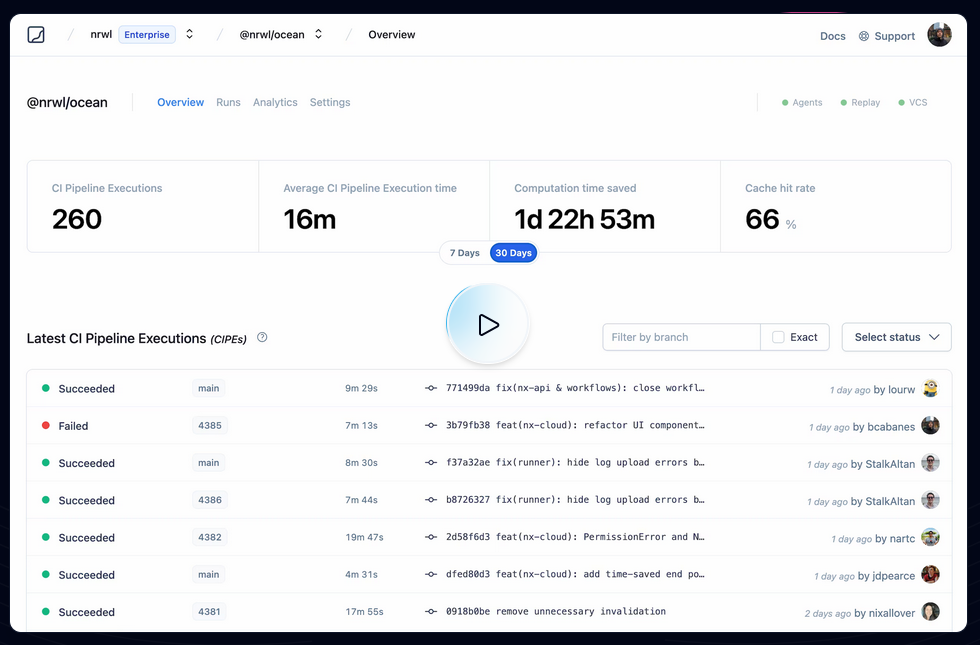
Je trouve cela très intéressant. Après avoir testé Bazel sans résultat concluant, sur la période 2018 à 2022, j'ai souvent cherché un outil comme Nx ou Turborepo, c'est-à-dire :
- Build distribué en parallèle sur différentes machines
- Partage de cache entre l'équipe de développement et les pipelines CI/CD
By default, Nx caches task results locally. The biggest benefit of caching comes from using remote caching in CI, where you can share the cache between different runs. Nx comes with a managed remote caching solution built on top of Nx Cloud.
To enable remote caching, connect your workspace to Nx Cloud by running the following command...
Je me demande si Nx permet de self host un composant de remote caching et si oui, je me demande si ce composant est open source ou non 🤔.
À noter que Turborepo permet de self host son propre service de remote cache : voir Turborepo - Remote Cache Self-hosting.
D'après mes recherches, Nx a été créé en juillet 2017, par Victor Savkin, un ancien développeur d'Angular chez Google. Selon cette description :
Software Engineer at Google (San Francisco Bay Area) between Jul 2014 - Dec 2016
One of the main developers of Angular 2. I've developed the dependency injection, change detection, forms, and router modules.
je pense que c'est pendant cette mission qu'il a eu l'idée de créer nx.
En janvier 2018, un second développeur Jason Jean, l'a rejoint sur le projet.
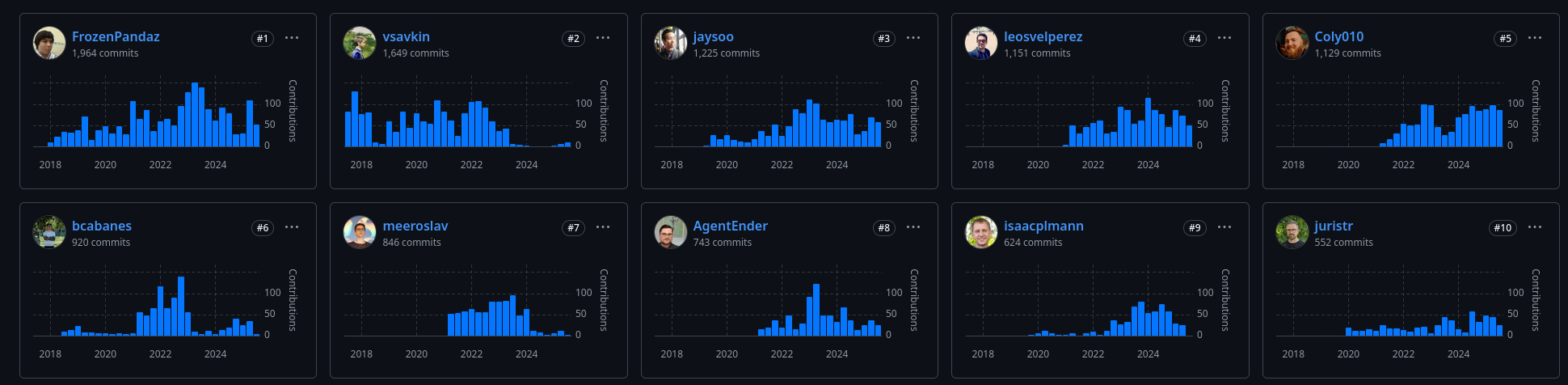
J'ai l'impression que Victor Savkin le CEO, n'a plus le temps de développer sur le projet depuis juillet 2023. Je pense que c'est à partir de là que le projet a eu de la traction.
Première description du gestionnaire de projet de mes rêves
Introduction
Cela fait depuis 2022 que je souhaite prototyper un outil de gestion de tâches (issues) avec certaines fonctionnalités que je n'ai trouvées dans aucun outils Open source ou closed-source.
En novembre 2022, j'ai commencé le tout début d'un modèle de données PostgreSQL, mais je n'ai pas continué.
Je souhaite, dans cette note, présenter mon idée de prototype, présenter les fonctionnalités que j'aimerais implémenter.
Nom du projet : Projet 24 - Prototyper le gestionnaire de projet de mes rêves
Ces idées de fonctionnalité sont tirées de besoin personnel que j'ai rencontré depuis 2018, dans mes différents projets professionnel en équipe.
Pour réduire mon temps de rédaction de cette note et la publier au plus tôt, je ne souhaite pas détailler ici l'origine de ces besoins.
Je souhaite juste décrire quelques fonctionnalités que je souhaite et quelque détail technique sans expliquer l'origine de mon besoin.
Sources d'inspiration
Mes principales sources d'inspiration :
- Certaines fonctionnalités issues et projects de GitHub et ses dernières améliorations.
- Certaines fonctionnalités Plan and track work de GitLab.
- Certaines fonctionnalités de Basecamp, par exemple, j'adore les Hill Charts (https://basecamp.com/hill-charts).
- Certaines fonctionnalités de Linear.
- Certaines fonctionnalités de OpenProject
Je me projette d'utiliser Projet 24 dans les framework de gestion de projets suivants :
Ainsi qu'avec la technologie sociale Sociocratie 3.0.
Liste de fonctionnalités en vrac
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
- Permettre d'attribuer à une issue une estimation basse et haute de temps d'implémentation.
- Permettre d'activer un Hill Charts sur toute issue.
- Permettre d'indiquer un niveau d'approximation d'une issue
- Permettre aux lectures d'une issue d'indiquer leur niveau de compréhension de l'issue
- Permettre de configurer la taille maximum en mots d'une issue. Pour forcer un certain niveau de synthèse.
- Permettre de calculer le poids d'une issue en faisant la somme basse et haute de toutes ses dépendances.
- Système inspiré de Tinder pour prioriser les issues. L'application présente deux issues choisies selon un algorithme Elo et invite l'utilisateur à désigner celle qu'il considère comme prioritaire.
- Implémenter un système de tags d'issues personnalisés où chaque utilisateur peut créer ses propres étiquettes. La visibilité de ces tags serait configurable : mode privé pour un usage personnel ou mode partagé pour les rendre disponibles aux autres utilisateurs.
- Permettre de créer des portfolios d'issue par utilisateurs.
- Pas de séparation des entités Epic (gestion de projet logiciel) / Issue contrairement à ce que fait GitLab.
- Permettre d'utilisation d'une extension Browser pour enrichir les pages GitHub, GitLab, Linear ou Forgejo avec les fonctionnalités de Projet 24.
- Permettre au Projet 24 d'améliorer une instance privé Forgejo avec un wrapper HTTP.
- Système de dashboard pratiquement identique à GitHub projects.
- Système de commentaire comme GitHub, mais avec un système de thread.
- Support de wikilink et alias au niveau de toutes les ressources texte.
- Support d'une fonctionnalité de publication de notes éphémères attachées à chaque utilisateur.
- Permettre la création d'issues ou de notes "flottantes". Une issue "flottante" n'appartient à aucune ressource spécifique — elle n'est rattachée ni à un projet, ni à un groupe. Cette fonctionnalité me semble essentielle et je compte la détailler dans une note dédiée prochainement.
- Proposer une extension Browser qui détecte automatiquement les issues liées à l'URL de la page actuelle. Cela permettrait d'accéder rapidement aux issues ou notes "flottantes" selon le contexte de navigation.
- Très bon support Markdown, contrairement aux implémentations de Slack, Notion ou Linear. Il devrait être possible de basculer entre le mode d'édition riche et le mode markdown. Le contenu copié doit générer du markdown valide dans le presse-papier.
- Respect strict des conventions Web : permettre l'ouverture de toutes les pages dans un nouvel onglet, etc.
- Mettre l'accent sur la performance de rendu des pages. Implémenter en priorité un système de métriques pour mesurer les temps de rendu.
- Proposer un système de génération de titre d'issue et de tag basé sur un LLM.
- Mettre en place un système qui utilise un LLM pour proposer automatiquement des titres d'issues et des tags.
- Alimenter une base de données vectorielle avec les descriptions d'issues et leurs commentaires pour activer la recherche sémantique.
Expérience utilisateur
Comme SilverBullet.mb, un outil fait dans un premier temps pour les hackers.
Détails techniques
- Stockage dans Elasticsearch pour faciliter les recherches par tags et plain text.
- Utilisation de nanoid de 5 caractères pour identifier les issues.
- Utilisation de Git hook pre-receive côté serveur pour importer des données (issues, notes, etc)
Journal du dimanche 22 juin 2025 à 23:34
Un collègue m'a fait découvrir Vercel Chat SDK (https://github.com/vercel/ai-chatbot) :
Chat SDK is a free, open-source template built with NextJS and the AI SDK that helps you quickly build powerful chatbot applications.
#JaimeraisUnJour prendre le temps de le décliner vers SvelteKit.
Aggregator - Backup Numeric Conversation System
Ce matin, j'ai eu l' #idée et l’envie de créer une appli d'archivage et de centralisation de toutes mes conversations numériques.
L'objectif ? Rassembler en un seul endroit, dans une interface web minimaliste, toutes mes discussions provenant de :
- ChatGPT
- Claude.ai
- Open WebUI
- Mes threads Mattermost
- Mes Mail
Le support des threads serait utile pour Mattermost et les mails. J'aimerais pouvoir sauvegarder tous ces messages au format brut original et en Markdown. Une fonction pour partager un message ou un thread serait aussi sympa.
Pour la persistance des données, je pense utiliser ElasticSearch avec son moteur vectoriel. Un LLM pourrait assigner automatiquement des tags à chaque conversation. J'aimerais que l'interface web soit minimaliste, orientée vitesse et exploration.
Pour la postérité, toutes ces données devraient être exportées en continu dans un Object Storage, sous un format YAML facilement compréhensible.
Je me demande si ce type d’application existe en Open source ou closed-source 🤔.
Journal du vendredi 20 juin 2025 à 15:49
Il y a quelques mois, j'ai publié la note : J'ai découvert « Timeline of AI model releases in 2024 ».
Aujourd'hui, #JaiDécouvert le site The Road To AGI 2015 - 2025 (https://ai-timeline.org/).
Ce projet est Open source, voici son repository : jam3scampbell/ai-timeline.

Il me permet d'avoir une d'ensemble des publications des 6 premiers mois de l'année 2025 :
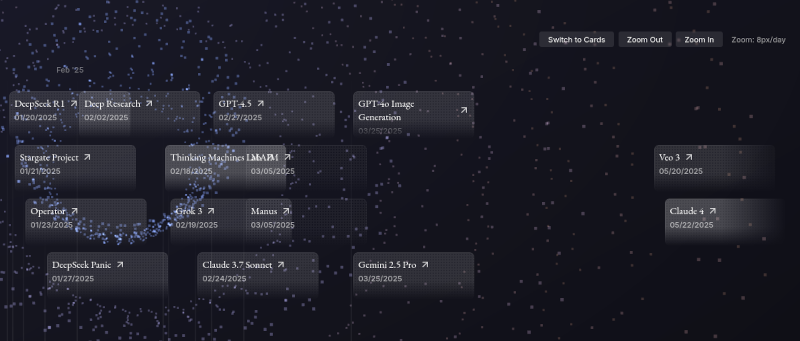
Bien que la réalisation de ce site soit techniquement réussie, après utilisation, je trouve qu'une simple liste Wikipedia répond mieux à mes besoins : https://en.wikipedia.org/wiki/List_of_large_language_models
Journal du vendredi 06 juin 2025 à 10:22
À ma connaissance, par défaut, sur la plupart des smartphones Android, Google Discover est affiché sur la page d'accueil après un swipe vers la gauche.
Je déteste cette fonctionnalité : elle détourne mon attention vers des informations futiles.
Comme je n'avais pas trouvé comment désactiver cette fonctionnalité sur mon précédent smartphone Oppo Find X3 Lite 5G, j'avais remplacé le launcher Android par défaut par Neo-Launcher.
Suite à ma migration vers un Fairphone 5, j'ai pris un peu de temps pour chercher des Android Launcher Open source et #JaiDécouvert ici le projet kvaesitso.
Je viens de l'installer avec succès et je peux enfin désactiver Google Discover 🙂.
Journal du dimanche 11 mai 2025 à 14:19
J'utilise Avante.nvim depuis le 12 janvier 2025. Je suis très satisfait, je trouve l'utilisation de cet outil agréable, bien que je sache que je maitrise seulement une petite partie de ses fonctionnalités.
Par exemple, je n'ai pas pris le temps de configurer la fonctionnalité RAG, ni la fonctionnalité Web Search Engines de avante.nvim.
Cela fait plusieurs semaines que je tombe sur le projet open-source aider.chat (https://aider.chat)
Aider lets you pair program with LLMs to start a new project or build on your existing codebase.
J'ai découvert ce projet ici le 20 avril 2025.
D'après ce que je comprends, Aider entre dans la catégorie des Terminaux Agents, comme par exemple Claude Code sortie en février 2025 ou OpenAI Codex CLI sorti en avril 2025.
Aider créé en 2023 par Paul Gauthier semble être un précurseur.
J'ai l'impression que les Terminaux Agents ont une plus large latitude d'action que les AI IDEs.